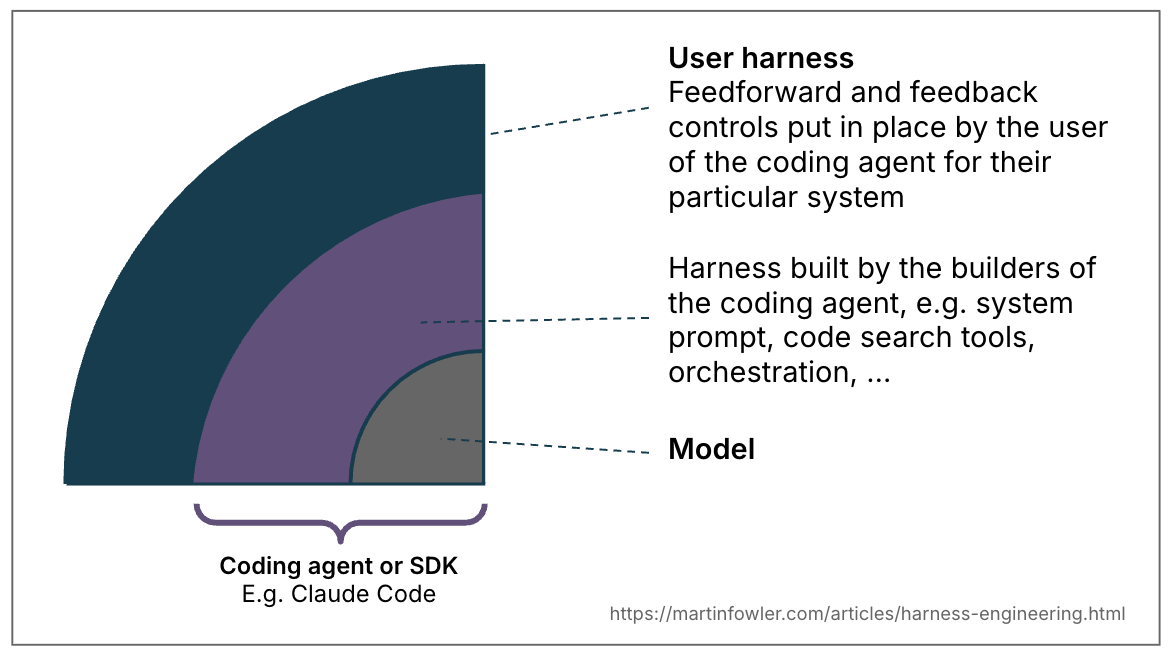
The term harness has emerged as a shorthand to mean everything in an AI agent except the model itself — Agent = Model + Harness. That is a very wide definition, and therefore worth narrowing down for common categories of agents. I want to take the liberty here of defining its meaning in the bounded context of using a coding agent.
In coding agents, part of the harness is already built in (e.g. via the system prompt, or the chosen code retrieval mechanism, or even a sophisticated orchestration system). But coding agents also provide us, their users, with many features to build an outer harness specifically for our use case and system.
A well-built outer harness serves two goals: it increases the probability that the agent gets it right in the first place, and it provides a feedback loop that self-corrects as many issues as possible before they even reach human eyes. Ultimately it should reduce the review toil and increase the system quality, all with the added benefit of fewer wasted tokens along the way.
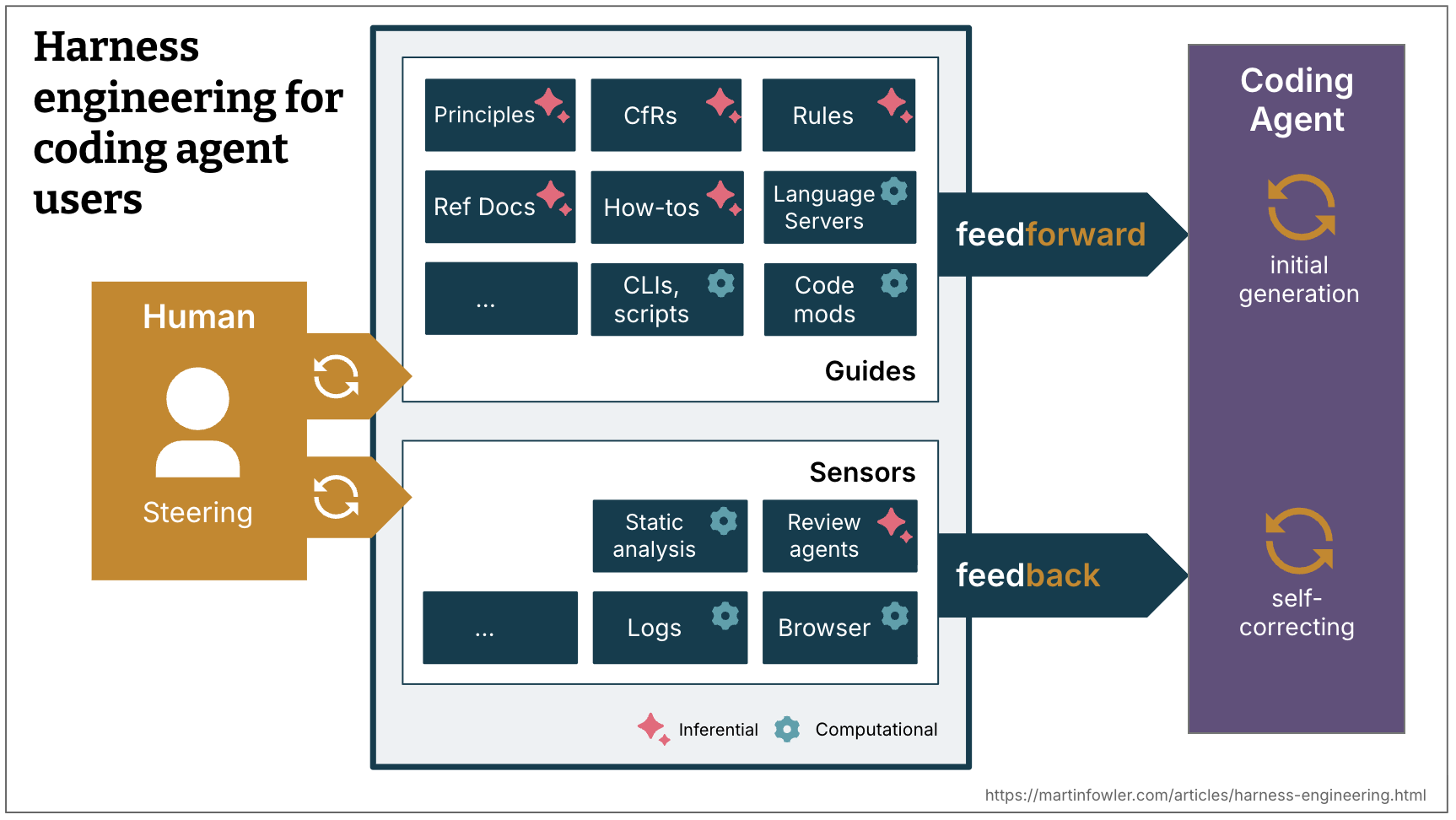
Feedforward and Feedback
To harness a coding agent we both anticipate unwanted outputs and try to prevent them, and we put sensors in place to allow the agent to self-correct:
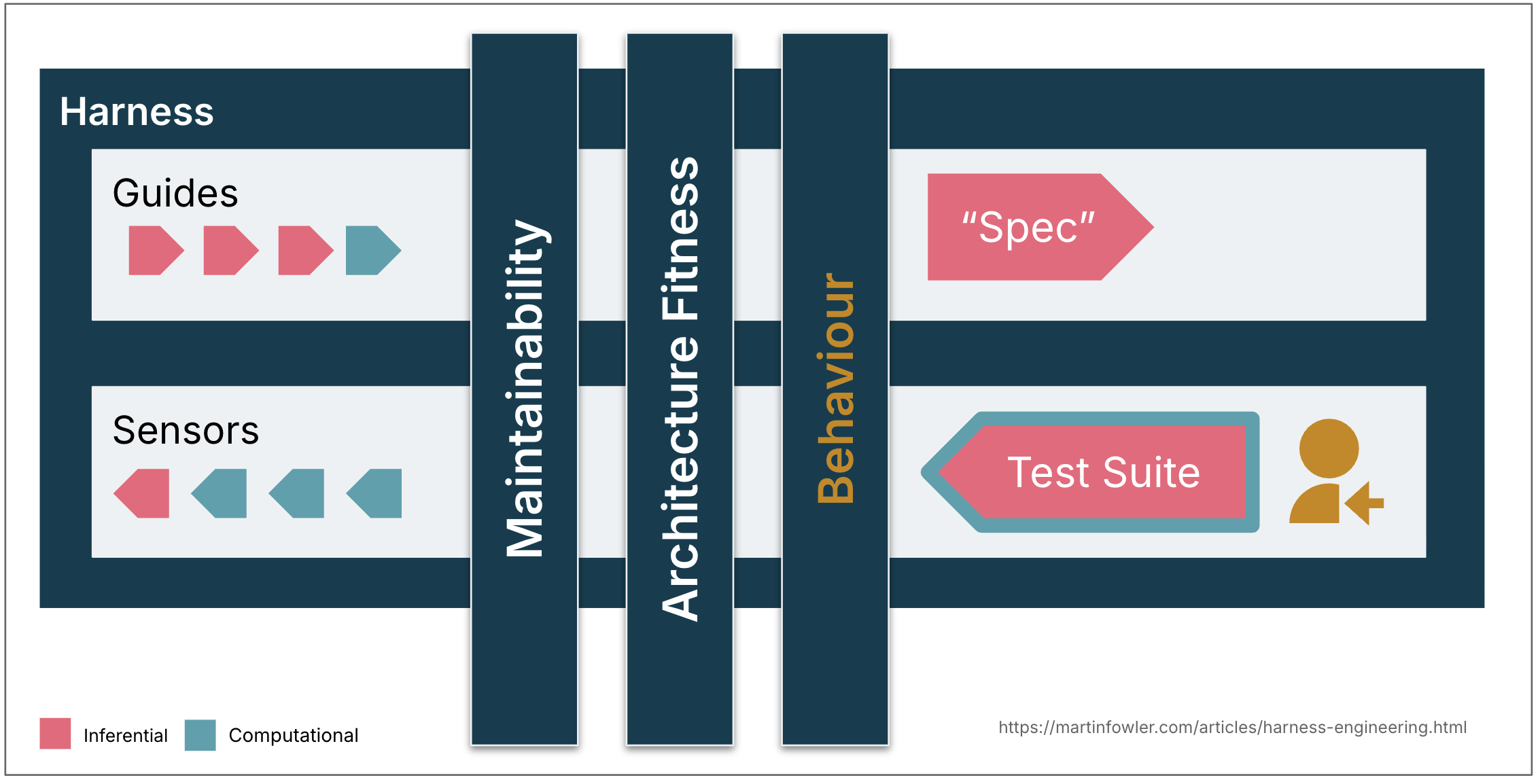
- Guides (feedforward controls) — anticipate the agent’s behaviour and aim to steer it before it acts. Guides increase the probability that the agent creates good results in the first attempt.
- Sensors (feedback controls) — observe after the agent acts and help it self-correct. Particularly powerful when they produce signals optimised for LLM consumption, e.g. custom linter messages that include instructions for the self-correction — a positive kind of prompt injection.
Separately, you get either an agent that keeps repeating the same mistakes (feedback-only) or an agent that encodes rules but never finds out whether they worked (feedforward-only).
Computational vs Inferential
There are two execution types of guides and sensors:
- Computational — deterministic and fast, run by the CPU. Tests, linters, type checkers, structural analysis. Run in milliseconds to seconds; results are reliable.
- Inferential — semantic analysis, AI code review, “LLM as judge.” Typically run by a GPU or NPU. Slower and more expensive; results are more non-deterministic.
Computational guides increase the probability of good results with deterministic tooling. Computational sensors are cheap and fast enough to run on every change, alongside the agent. Inferential controls are more expensive and non-deterministic, but allow us to provide rich guidance and add additional semantic judgment.
| Direction | Computational / Inferential | Example |
|---|---|---|
| Coding conventions | Feedforward, Inferential | AGENTS.md, Skills |
| Bootstrap instructions | Feedforward, Both | Skill with instructions and a bootstrap script |
| Code mods | Feedforward, Computational | A tool with access to OpenRewrite recipes |
| Structural tests | Feedback, Computational | A pre-commit hook running ArchUnit tests |
| Review instructions | Feedback, Inferential | Skills |
The Steering Loop
The human’s job is to steer the agent by iterating on the harness. Whenever an issue happens multiple times, the feedforward and feedback controls should be improved to make the issue less probable to occur in the future, or even prevent it.
We can also use AI to improve the harness itself. Coding agents now make it much cheaper to build custom controls and custom static analysis. Agents can help write structural tests, generate draft rules from observed patterns, scaffold custom linters, or create how-to guides from codebase archaeology.
Timing: Keep Quality Left
Teams who are continuously integrating have always faced the challenge of spreading tests, checks and human reviews across the development timeline according to their cost, speed and criticality. You want checks as far left in the path to production as possible, since the earlier you find issues, the cheaper they are to fix.
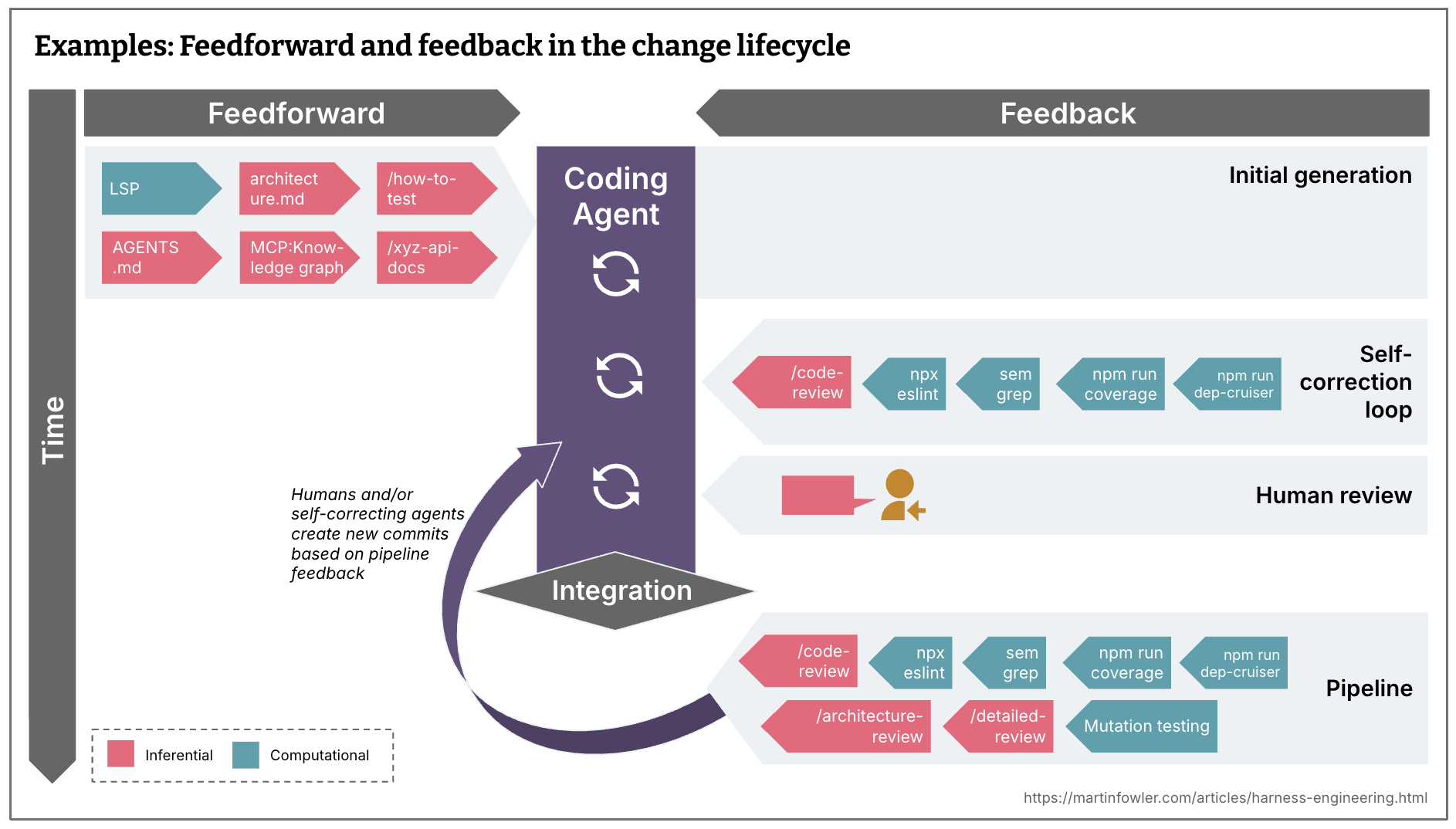
Before integration (fast, run on every change):
- LSP, architecture.md, how-to-test skills, AGENTS.md
/code-reviewskill,npx eslint, semgrep,npm run coverage,npm run dep-cruiser
Post-integration pipeline (more expensive):
/architecture-reviewskill,/detailed-reviewskill, mutation testing
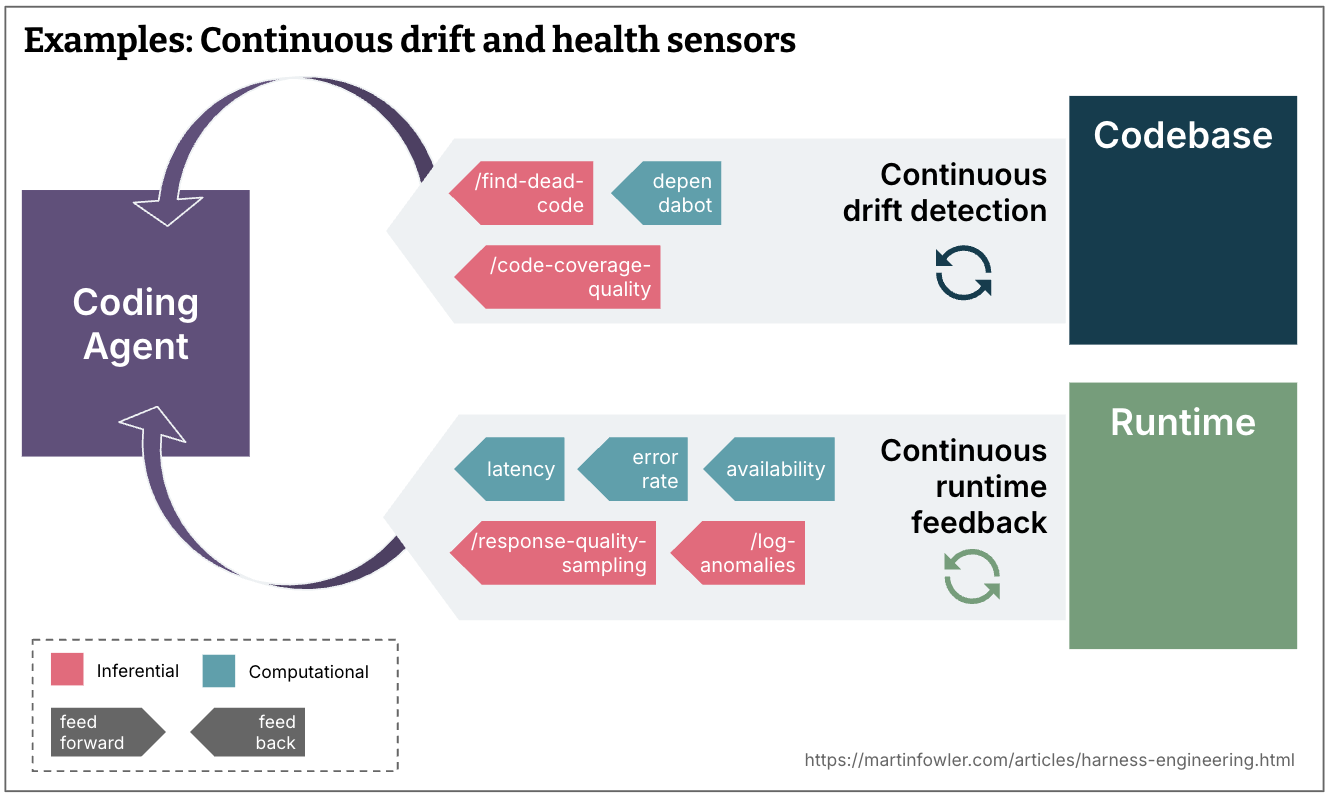
Continuous drift and health sensors (outside the change lifecycle):
- Dead code detection, test coverage quality analysis, dependency scanners
- Runtime feedback: degrading SLOs → agent suggestions, response quality sampling, log anomaly detection
Regulation Categories
The agent harness acts like a cybernetic governor, combining feedforward and feedback to regulate the codebase towards its desired state. It’s useful to distinguish between multiple dimensions of that desired state.
Maintainability Harness
This is currently the easiest type of harness, as we have a lot of pre-existing tooling.
- Computational sensors catch structural stuff reliably: duplicate code, cyclomatic complexity, missing test coverage, architectural drift, style violations. These are cheap, proven, and deterministic.
- LLMs can partially address problems requiring semantic judgment — semantically duplicate code, redundant tests, brute-force fixes, over-engineered solutions — but expensively and probabilistically. Not on every commit.
- Neither catches reliably some of the higher-impact problems: misdiagnosis of issues, overengineering and unnecessary features, misunderstood instructions. Correctness is outside any sensor’s remit if the human didn’t clearly specify what they wanted in the first place.
Architecture Fitness Harness
Groups guides and sensors that define and check the architecture characteristics of the application — basically architectural fitness functions.
Examples:
- Skills that feed forward performance requirements, and performance tests that feed back whether the agent improved or degraded them.
- Skills that describe coding conventions for observability (like logging standards), and debugging instructions that ask the agent to reflect on the quality of the logs it had available.
Behaviour Harness
This is the elephant in the room — how do we guide and sense if the application functionally behaves the way we need it to?
Currently, most people who give high autonomy to coding agents do this:
- Feedforward: A functional specification (from a short prompt to multi-file descriptions)
- Feedback: Check if the AI-generated test suite is green, has high coverage, maybe monitor quality with mutation testing, then combine with manual testing.
This puts a lot of faith into AI-generated tests — that’s not good enough yet. We still have a lot to figure out to get good harnesses for functional behaviour that increase confidence enough to reduce supervision and manual testing.
Harnessability
Not every codebase is equally amenable to harnessing:
- A strongly typed language naturally has type-checking as a sensor
- Clearly definable module boundaries afford architectural constraint rules
- Frameworks like Spring abstract away details the agent doesn’t have to worry about, implicitly increasing the agent’s chances of success
This plays out differently for greenfield versus legacy. Greenfield teams can bake harnessability in from day one — technology decisions and architecture choices determine how governable the codebase will be. Legacy teams, especially with applications that have accrued a lot of technical debt, face the harder problem: the harness is most needed where it is hardest to build.
Harness Templates
Most enterprises have a few common topologies that cover 80% of what they need — business services exposing data via APIs, event processing services, data dashboards. In many mature engineering organizations these topologies are already codified in service templates.
These might evolve into harness templates in the future: a bundle of guides and sensors that leash a coding agent to the structure, conventions and tech stack of a topology. Teams may start picking tech stacks and structures partly based on what harnesses are already available for them.
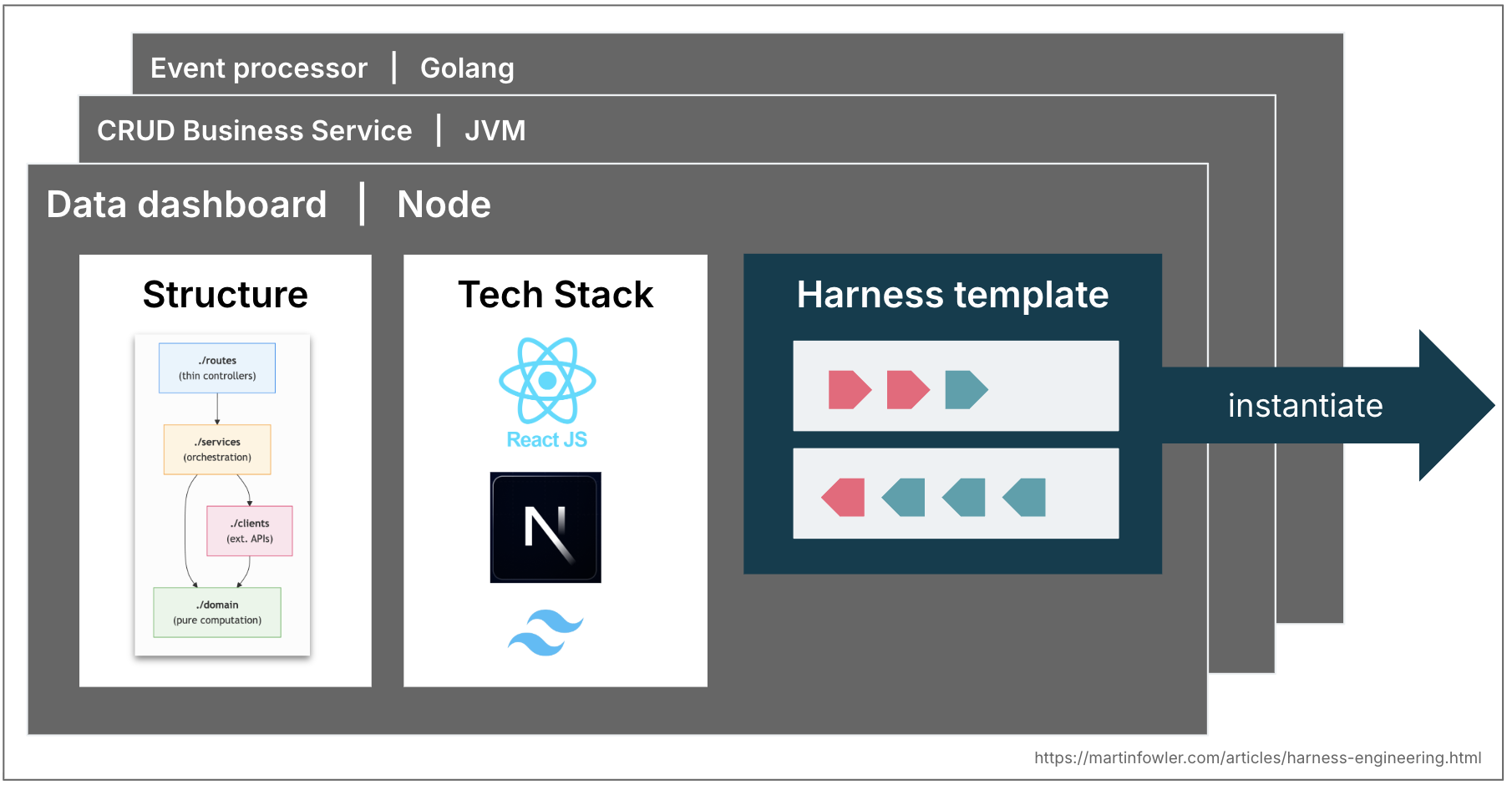
We would of course face similar challenges as with service templates. As soon as teams instantiate them, they start to fall out of sync with upstream improvements. Harness templates would face the same versioning and contribution problems, maybe even worse with non-deterministic guides and sensors that are harder to test.
The Role of the Human
As human developers we bring our skills and experience as an implicit harness to every codebase. We absorbed conventions and good practices, we have felt the cognitive pain of complexity, and we know that our name is on the commit. We also carry organisational alignment — awareness of what the team is trying to achieve, which technical debt is tolerated for business reasons, and what “good” looks like in this specific context. We go in small steps and at our human pace, which creates the thinking space for that experience to get triggered and applied.
A coding agent has none of this: no social accountability, no aesthetic disgust at a 300-line function, no intuition that “we don’t do it that way here,” and no organisational memory. It doesn’t know which convention is load-bearing and which is just habit, or whether the technically correct solution fits what the team is trying to do.
Harnesses are an attempt to externalise and make explicit what human developer experience brings to the table, but it can only go so far. Building a coherent system of guides and sensors and self-correction loops is expensive, so we have to prioritise with a clear goal in mind: A good harness should not necessarily aim to fully eliminate human input, but to direct it to where our input is most important.
Open Questions
Here are some harness-related examples from the current discourse:
- An OpenAI team documented their harness: layered architecture enforced by custom linters and structural tests, and recurring “garbage collection” that scans for drift and has agents suggest fixes. Their conclusion: “Our most difficult challenges now center on designing environments, feedback loops, and control systems.”
- Stripe’s write-up about their minions describes pre-push hooks that run relevant linters based on heuristics, highlighting how important “shift feedback left” is to them.
- Mutation and structural testing — computational feedback sensors that have been underused in the past — are now having a resurgence.
- Increased chatter among developers about integrating LSPs and code intelligence in coding agents: examples of computational feedforward guides.
- Teams at Thoughtworks are tackling architecture drift with both computational and inferential sensors, e.g. increasing API quality with a mix of agents and custom linters, or increasing code quality with a “janitor army.”
There’s plenty still to figure out. How do we keep a harness coherent as it grows, with guides and sensors in sync, not contradicting each other? How far can we trust agents to make sensible trade-offs when instructions and feedback signals point in different directions? If sensors never fire, is that a sign of high quality or inadequate detection? We need a way to evaluate harness coverage and quality similar to what code coverage and mutation testing do for tests.
Building this outer harness is emerging as an ongoing engineering practice, not a one-time configuration.